REINFORCE Adversarial Attacks on Large Language Models: An Adaptive, Distributional, and Semantic Objective
Abstract
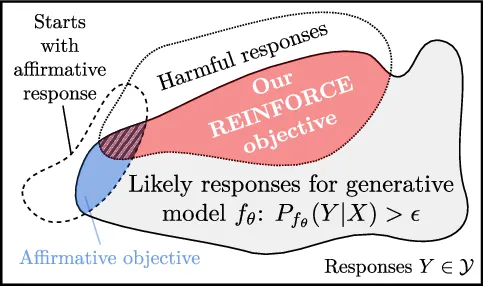
To circumvent the alignment of large language models (LLMs), current optimization-based adversarial attacks usually craft adversarial prompts by maximizing the likelihood of a so-called affirmative response. An affirmative response is a manually designed start of a harmful answer to an inappropriate request. While it is often easy to craft prompts that yield a substantial likelihood for the affirmative response, the attacked model frequently does not complete the response in a harmful manner. Moreover, the affirmative objective is usually not adapted to model-specific preferences and essentially ignores the fact that LLMs output a distribution over responses. If low attack success under such an objective is taken as a measure of robustness, the true robustness might be grossly overestimated. To alleviate these flaws, we propose an adaptive and semantic optimization problem over the population of responses. We derive a generally applicable objective via the REINFORCE policy-gradient formalism and demonstrate its efficacy with the state-of-the-art jailbreak algorithms Greedy Coordinate Gradient (GCG) and Projected Gradient Descent (PGD). For example, our objective doubles the attack success rate (ASR) on Llama3 and increases the ASR from 2% to 50% with circuit breaker defense.
Links
Cite
Please cite our paper if you use the method in your own work:
@inproceedings{geisler2025_reinforce_attacks_llms,
title = {REINFORCE Adversarial Attacks on Large Language Models: An Adaptive, Distributional, and Semantic Objective},,
author = {Geisler, Simon and Abdalla, M. H. I. and Cohen-Addad, Vincent and Gasteiger, Johannes and G\"unnemann, Stephan},
booktitle={arXiv:2502.17254}year = {2025},}